

Data has become one of the most valuable assets for modern businesses. Organizations across industries rely on data analytics, artificial intelligence, machine learning, and business intelligence tools to make informed decisions, improve customer experiences, and drive operational efficiency. However, raw data collected from multiple sources is often unstructured, inconsistent, and difficult to analyze directly.
To transform raw data into meaningful business insights, companies use data integration pipelines that move, process, and prepare information for analytics platforms and data warehouses. Two of the most widely used approaches in modern data engineering are ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform).
Although both methods aim to prepare data for analysis, they differ significantly in architecture, processing methods, scalability, and performance. As cloud computing and big data technologies continue evolving, many organizations are shifting from traditional ETL models toward modern ELT architectures.
Understanding the differences between ETL and ELT pipelines is essential for businesses building scalable, efficient, and future-ready data infrastructure.
Understanding ETL Pipelines –
ETL stands for Extract, Transform, and Load. It is a traditional data integration process that has been widely used for decades in enterprise data warehousing environments.
In an ETL pipeline, data is first extracted from various sources such as databases, CRM systems, applications, APIs, spreadsheets, or cloud platforms. Once extracted, the data is transformed into a structured and standardized format before being loaded into a target data warehouse or analytics system.
The transformation stage may include cleaning data, removing duplicates, validating records, aggregating information, applying business rules, and converting formats.
ETL pipelines were originally designed for on-premise data warehouses where storage and processing power were expensive. Transforming data before loading helped reduce storage requirements and improve query efficiency.
Understanding ELT Pipelines –
ELT stands for Extract, Load, and Transform. Unlike ETL, ELT pipelines load raw data directly into a target storage system before performing transformations.
In this approach, data is extracted from source systems and immediately loaded into modern cloud-based data warehouses or data lakes. Transformations are then performed within the target system using its computational power and scalability.
ELT has gained popularity due to the rise of cloud computing platforms such as Snowflake, Google BigQuery, Amazon Redshift, and Databricks. These platforms provide massive storage capacity and high-performance processing capabilities that make in-platform transformations more efficient.
Because raw data is preserved, ELT pipelines offer greater flexibility for analytics, machine learning, and future data processing needs.
Key Difference Between ETL and ELT –
The main difference between ETL and ELT lies in the order of transformation and loading.
In ETL, data is transformed before loading into the warehouse. In ELT, raw data is loaded first and transformed later within the destination platform.
This architectural difference significantly impacts scalability, performance, cost, flexibility, and processing speed.
ETL vs ELT Comparison Table –
| Feature | ETL | ELT |
|---|---|---|
| Full Form | Extract, Transform, Load | Extract, Load, Transform |
| Transformation Stage | Before loading data | After loading data |
| Processing Location | External processing server | Inside data warehouse |
| Storage Requirement | Lower storage usage | Higher storage usage |
| Scalability | Limited scalability | Highly scalable |
| Performance | Slower for large datasets | Faster with cloud platforms |
| Data Flexibility | Structured data focus | Supports structured and unstructured data |
| Best For | Traditional enterprise systems | Modern cloud-based analytics |
| Infrastructure | On-premise environments | Cloud-native architectures |
| Data Availability | Delayed access | Near real-time access |
How ETL Pipelines Work –
Traditional ETL pipelines follow a structured workflow designed to ensure data consistency and quality before storage.
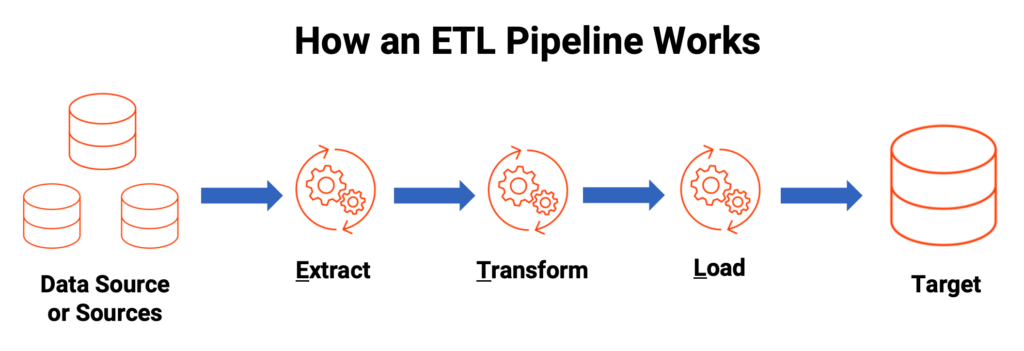
Step 1: Data Extraction
Data is collected from multiple systems including databases, ERP systems, APIs, applications, spreadsheets, and third-party platforms.
Step 2: Data Transformation
The extracted data is cleaned, standardized, validated, and formatted according to business requirements. Common transformations include filtering, deduplication, aggregation, normalization, and data enrichment.
Step 3: Data Loading
After transformation, the cleaned data is loaded into a target data warehouse for reporting and analytics.
This process ensures that only processed and validated information enters the warehouse.
How ELT Pipelines Work –
Modern ELT pipelines follow a more flexible cloud-native approach.
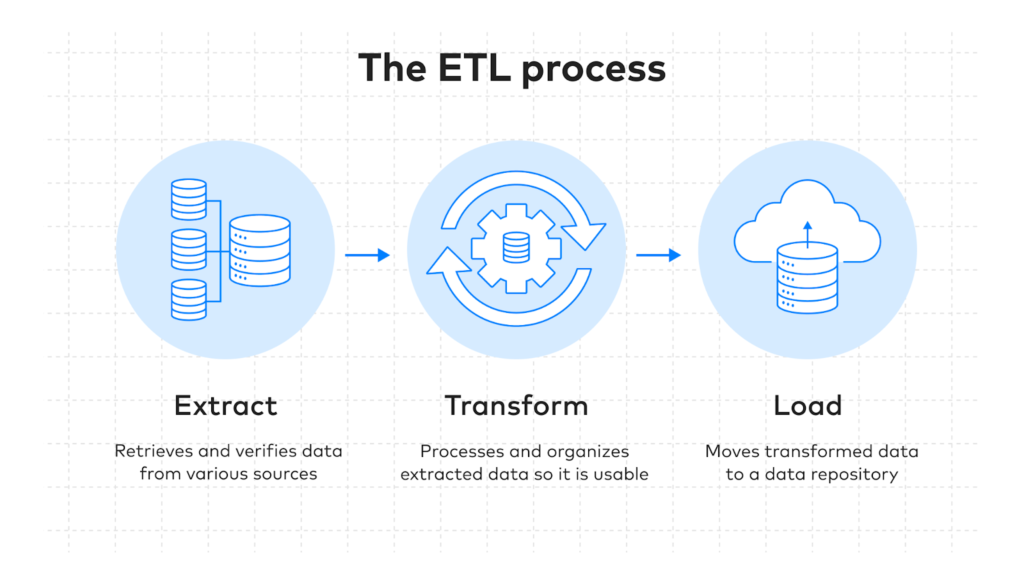
Step 1: Data Extraction
Raw data is extracted from multiple data sources just like in ETL systems.
Step 2: Data Loading
Instead of transforming data first, ELT pipelines load raw information directly into a cloud data warehouse or data lake.
Step 3: Data Transformation
Transformations occur within the target platform using SQL queries, distributed computing engines, or cloud-native processing tools.
This architecture allows businesses to retain raw data for future analysis while supporting faster and more scalable processing.
Why Modern Businesses Prefer ELT –
The rise of cloud computing has significantly changed how organizations manage data infrastructure. Modern businesses increasingly prefer ELT because cloud data warehouses provide scalable storage and powerful processing capabilities at lower costs.
ELT also supports modern analytics requirements more effectively. Businesses today work with massive volumes of structured, semi-structured, and unstructured data generated from websites, IoT devices, applications, social media, and customer interactions.
Because ELT stores raw data, organizations gain greater flexibility for future analysis, machine learning models, and advanced reporting.
Another major advantage is speed. ELT pipelines enable faster ingestion of large datasets, making near real-time analytics possible.
Data teams also benefit from simplified pipeline architectures since cloud platforms handle much of the computational workload internally.
Advantages of ETL Pipelines –
Although ELT is growing rapidly, ETL still remains valuable for many enterprise environments.
One major advantage of ETL is improved data quality control before storage. Since transformations occur prior to loading, businesses can ensure that only validated and structured data enters the warehouse.
ETL pipelines are also useful in highly regulated industries where strict compliance and governance standards require controlled data processing workflows.
Organizations with legacy systems or limited cloud infrastructure may also prefer ETL because it reduces storage costs and minimizes unnecessary data retention.
Additionally, ETL workflows are often easier to optimize for predefined reporting requirements.
Challenges Associated with ETL and ELT –
Both ETL and ELT approaches come with operational challenges.
ETL systems may struggle with scalability as data volumes grow. Complex transformations performed before loading can create processing bottlenecks and increase infrastructure costs.
ETL pipelines are also less flexible because transformed data may lose raw details needed for future analysis.
ELT systems, while highly scalable, require strong cloud infrastructure and data governance practices. Since raw data is stored directly, organizations must manage larger storage requirements and stronger security controls.
Data quality management can also become more complex in ELT environments if transformation logic is not properly governed.
Modern Technologies Supporting ETL and ELT –
Modern data engineering ecosystems support both ETL and ELT pipelines using specialized tools and cloud platforms.
Popular ETL tools include Informatica, Talend, SSIS, and Apache NiFi. These platforms provide structured workflows for data integration and transformation.
ELT workflows are commonly powered by cloud-native platforms such as Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse Analytics, and Databricks.
Open-source technologies such as Apache Spark, Airflow, Kafka, and dbt are also widely used for building scalable data pipelines and orchestration systems.
Automation, AI, and machine learning are increasingly integrated into pipeline management to improve performance monitoring, anomaly detection, and workflow optimization.
ETL vs ELT: Which One Should Businesses Choose?
Choosing between ETL and ELT depends on several factors including business requirements, infrastructure, data volume, compliance needs, and analytics goals.
Organizations using traditional on-premise data warehouses or strict governance models may still benefit from ETL pipelines due to their structured processing approach.
However, businesses adopting cloud-native architectures, big data analytics, and AI-driven operations often prefer ELT because of its scalability, speed, and flexibility.
In many cases, companies now use hybrid approaches that combine elements of both ETL and ELT depending on workload requirements and operational priorities.
The decision ultimately depends on balancing performance, cost, governance, and future scalability needs.
The Future of Data Pipelines –
The future of data engineering is moving toward highly automated, cloud-native, and real-time architectures. ELT is expected to continue growing as businesses increasingly adopt cloud computing and AI-powered analytics platforms.
Modern data pipelines are becoming more intelligent through automation, metadata management, and machine learning-driven optimization.
Real-time streaming architectures using technologies such as Apache Kafka and cloud event streaming platforms are also transforming how organizations process and analyze data.
Additionally, concepts such as DataOps, data mesh architectures, and lakehouse platforms are reshaping enterprise data strategies.
As data volumes continue increasing globally, scalable and flexible pipeline architectures will remain critical for business intelligence and digital transformation initiatives.
Conclusion –
ETL and ELT pipelines are essential components of modern data engineering and analytics infrastructure. While both approaches serve the purpose of integrating and preparing data for business use, they differ significantly in processing methods, scalability, flexibility, and architecture.
Traditional ETL pipelines remain valuable for controlled enterprise environments and compliance-focused workflows, while modern ELT pipelines are increasingly preferred for cloud-based analytics, big data processing, and AI-driven applications.
As organizations continue embracing digital transformation and cloud computing, understanding the strengths and limitations of ETL and ELT becomes increasingly important for building efficient and future-ready data ecosystems.
Businesses that choose the right data pipeline strategy can improve operational efficiency, accelerate analytics capabilities, and unlock greater value from their growing data assets.